
Is there really a stack behind the depth first search (DFS) algorithm and what is the generating order of the nodes?
Recently, I had a discussion with the TA of CS161 (Fundamental of Artificial Intelligence) about DFS algorithm. There was a problem in the midterm that required us to label the order of the generated nodes in DFS and the breadth first search (BFS) algorithm. It is known that, for BFS, checking the goal at generating stage and expanding stage have a huge difference. When testing the goal at generating stage, we can immediately stop when we find one of the nodes that will be expanded later is the goal, while if at expanding stage, we have to expand all of the other nodes before the goal node at the same level. In worst case, the time complexity differs in b times, where b denotes the branching factor.
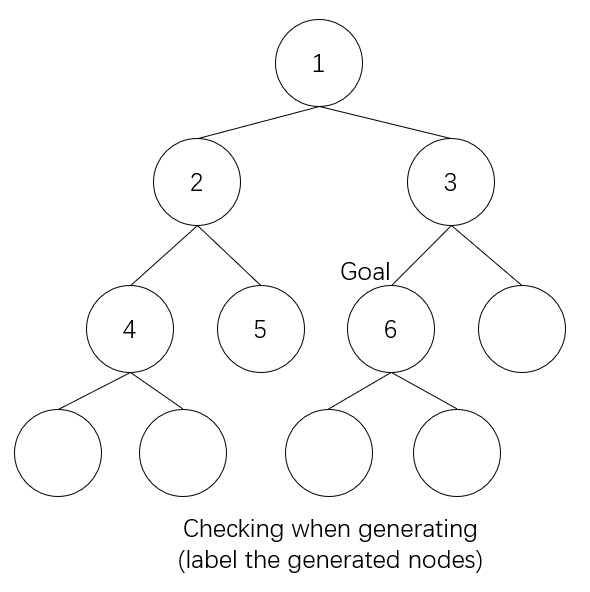
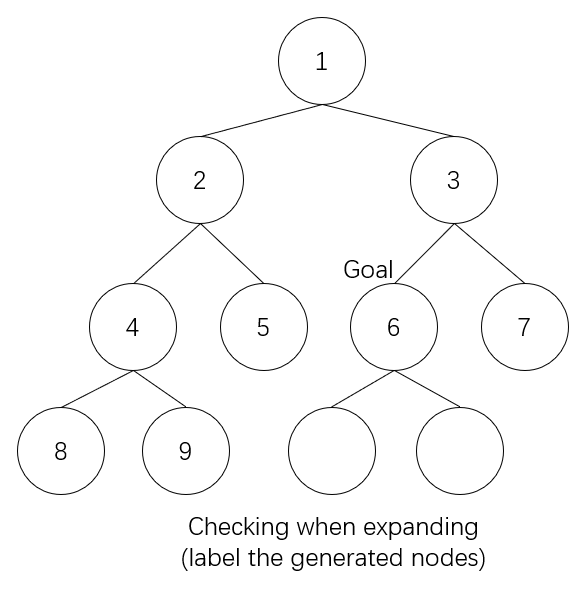
But what about DFS? What is its generating order?
The answer is a little tricky. But if you have learnt about it in class, you should have the right answer. If we use the stack data structure to implement the algorithm (note that we use a special container ‘fringe’, which is similar to, but different from stack, to hold the generated nodes), the order would be like this.
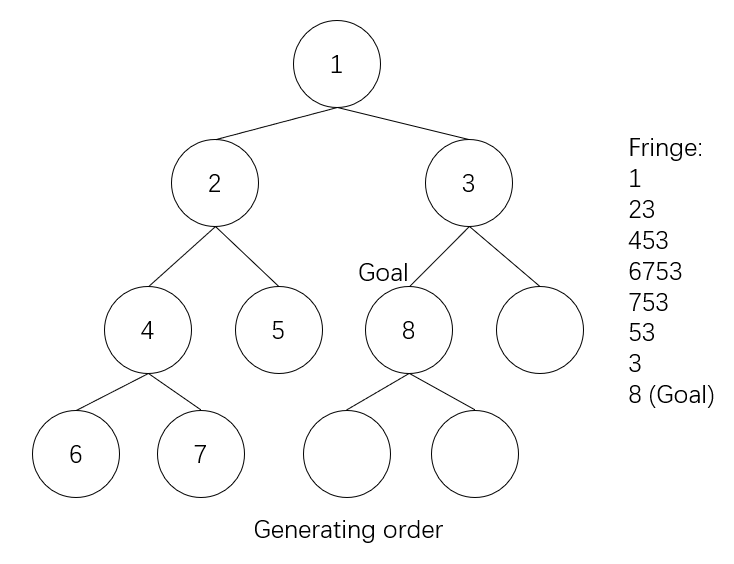
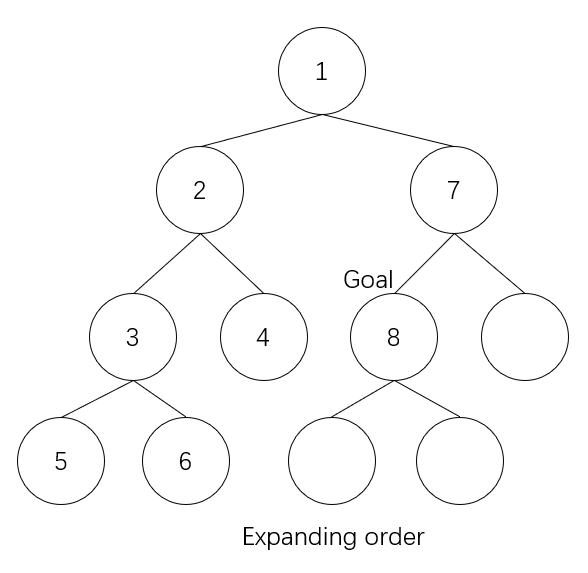
However, if we use recursion to implement the algorithm, there will not be a stack.
class Node{
public:
int value;
vector<Node*> child;
Node(int v):value(v){}
};
void dfs(Node* t){
cout << t->value << " ";
if(t->child.size()==0) return;
for(int i = 0;i<t->child.size();i++){
dfs(t->child[i]);
}
}
In the above implemention, you will ‘surprisingly’ find that stack is no more needed and if you go through the proceedure, generating order and expanding order will be the same. It seems like the node is generated and expanded at the same time. What causes this disagreement with our common sense?
First, let us solve the stack mystery. Do we really need stack to implement DFS? The answer is yes. Though there might not be an explicit stack in the above implementation, we do use a stack during the execution. The stack is implicitly used when calling the function recursively. If you have taken classes about operating systems, you should know that every time we call a function, a new memory space is allocated for this function, pushed onto the current memory stack.
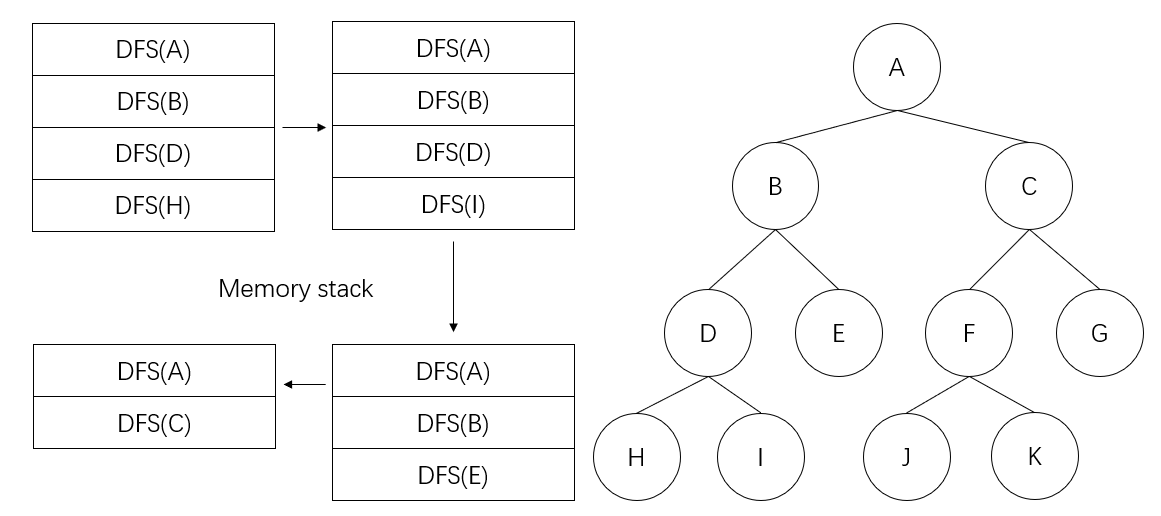
So yes, even if you do not use a stack in storing the nodes, you do use a stack to call the functions. The answer to whether there is a stack behind DFS is yes.
How about the second the question?
The implementation above uses a very trick type, pointer. It points to the memory space where the node is stored. In this case, the generating order is indeed the same as the expanding order, since we do nothing but pass the pointer to the function. But what if the language does not support pointer or address operation? Like this.
class Node{
public:
int value;
vector<Node> child;
Node(int v):value(v){}
};
void dfs(Node t){
cout << t.value << " ";
if(t.child.size()==0) return;
for(int i = 0;i<t.child.size();i++){
dfs(t.child[i]);
}
}
When we pass the node to the function, we acctually push the whole node onto the memory stack.
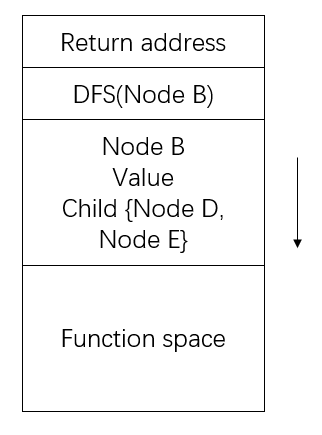
In this case, we have already generated the child nodes of the passed node, which would lead to the difference between generating order and expanding order. So the answer to the second question really depends on how you treat it. When you consider implementing with pointer, there should be no difference. Otherwise, you have a different order of generating from expanding.
Though it seems quite right from my perspective, I am still open to this discussion. Please correct me if anything is wrong.
Peace.